December 9, 2022
Update from @carperai on their use of Reinforcement Learning from Human Feedback (RLHF) to build a large language model (LLM). Maybe the next big thing in #AI will come from here >
Illustrating Reinforcement Learning from Human Feedback (RLHF) https://t.co/h4whC5LhcE https://t.co/aPaOUyKEhz
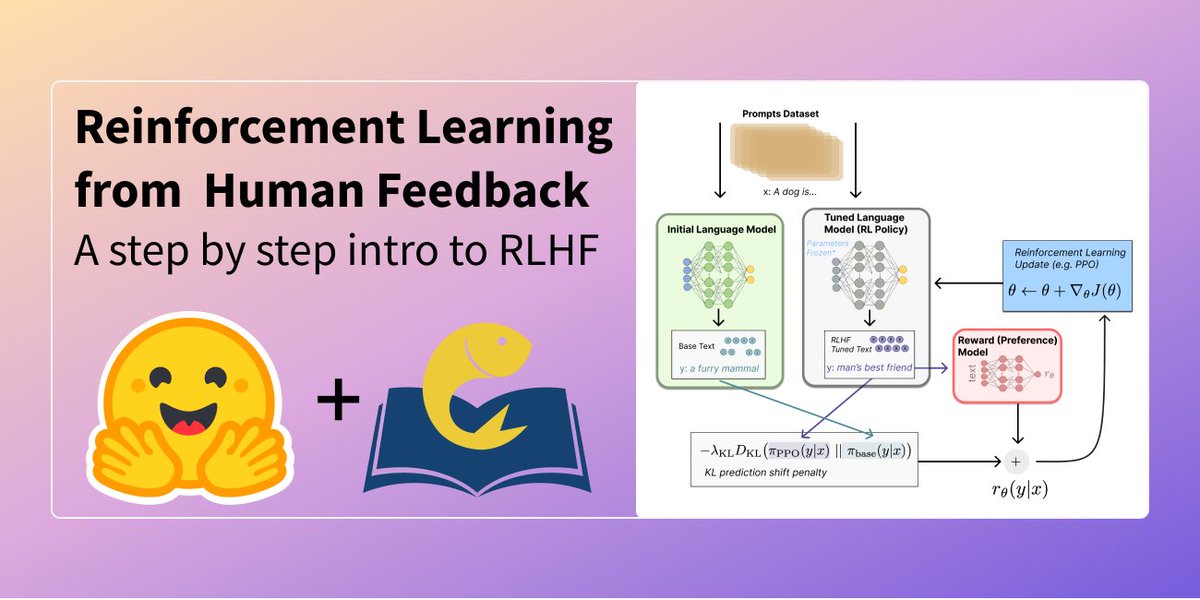
Original tweet: https://twitter.com/giano/status/1601267074910900224
This is one of the many thoughts I post on Twitter on daily basis. They span many disciplines, including art, artificial intelligence, automation, behavioral economics, cloud computing, cognitive psychology, enterprise management, finance, leadership, marketing, neuroscience, startups, and venture capital.
I archive all my tweets here.
I archive all my tweets here.