NoOps: Misguided Hopes, New Ideas, And Three Paths Towards An Attainable Future
In one of the many executive-level conversations I routinely have, a client asked to talk about “NoOps”. The client is a vast and sophisticated company, continent-wide in terms of market share. They are trying to evolve the IT Operations practice so that it can support growth well beyond the current scale without crumbling under the weight of the organization.
The leading executive and his team wanted to investigate the definition of “NoOps” and what could be considered an ambitious vision for the future.
I have advocated and advised about automation since 2004, working with hundreds of Fortune and Global Fortune companies around the world. However, questions about “NoOps” started to appear only after the advent of serverless computing platforms, just five years ago.
The topic is vast, confusing, and populated by misguided hopes, so I thought this was the perfect occasion to write something about it.
I won’t mention any specific solution that addresses the following points, keeping the conversation vendor-neutral, but feel free to reach out for more details.
- Evolving Definitions
- Roadblocks to NoOps
- Paths Towards an Attainable Future
- No(rmalized)Ops
- No(tMy)Ops
- No(Human)Ops
- A Roadmap Towards an Approximation of NoOps
Evolving Definitions
As far as I can tell, the analysis firm Forrester Research was the first to use the term “NoOps” in a research paper dated Apr 2011.
In their original intent, NoOps was an evolution of the already trendy concept of “DevOps” where the application lifecycle is devoid of human labour*.
Over the subsequent years, people have expanded the Forrester idea beyond the boundaries of the application lifecycle. Like many other technology labels coined in the last two decades (e.g., Private Cloud, DevOps, AIOps), the definition forged by its creator has been all but objective. People have inferred different meanings from the name rather than bothering to study the original articulation.
The predominant interpretation of “NoOps” I hear these days is that automation completely replaces human labour in every aspect of IT Operations, and this is the definition I’ll refer to for the rest of this blog post.
First, I want to clarify why I’m using this specific definition.
Automation or not, IT Operations go beyond the activities related to the application lifecycle, from provisioning to retirement. IT Operations also encompasses a large number of discrete operations that are not associated with any specific application or its life cycle state—for example, a network reconfiguration after an acquisition and subsequent merge, or a security investigation.
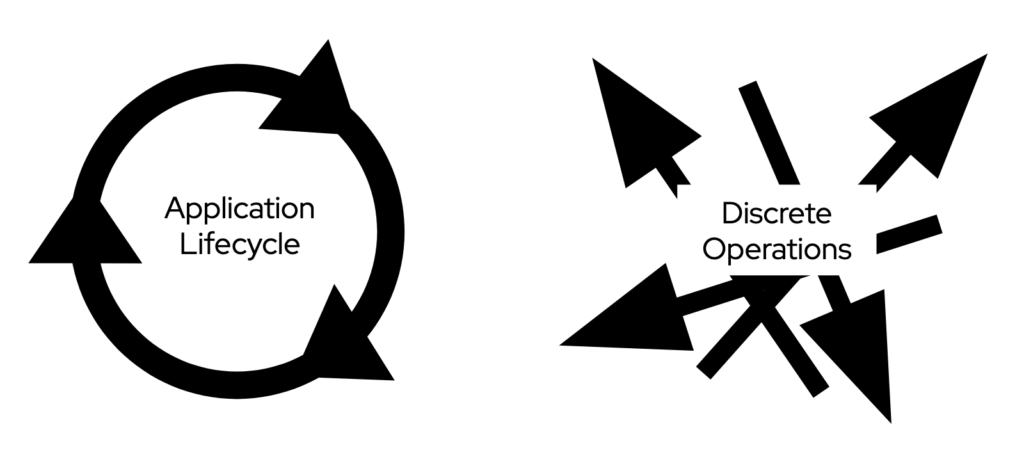
IT professionals exclusively focused on application development and delivery tend to think about IT Operations just in the context of the application life cycle. Accordingly, they think about “NoOps” as the attempt to automate that life cycle. While this is understandable, it’s worth asking what will happen once they achieve the goal.
Even those IT professionals focused on application development and delivery will likely see a value in expanding the automation effort to discrete operations as well. Why constrain the company’s agility to application delivery when you can automate a whole business process and then the entire IT environment?

So, eventually, the broader interpretation of “NoOps”, encompassing both application life cycle and discrete operations, is the one that I’d expect to become predominant. The one that is worth considering when we talk about a long-term roadmap.
Roadblocks to NoOps
If a customer asks about “NoOps” and gives you the freedom to imagine and spell out an ambitious future, it’s very tempting to answer that the key to “NoOps” is APIs everywhere.
The problem is that an ambitious future must still be attainable. Unfortunately, even if we are in 2020, a programmable IT based on APIs everywhere seems out of reach for the overwhelming majority of organizations out there.
For once, even the most recent commercial off-the-shelf solutions don’t always offer an API that guarantees parity with the UI counterpart. Let alone, custom-built applications that organizations continually develop internally. API parity may be the vendor’s ambition, but, in my experience, it remains an aspiration for most software in an enterprise application portfolio.
So the question has to become: “Can I reach NoOps without APIs everywhere? Can I, for example, start from existing automation applied to my current IT environment?”
That is a more pragmatic question and can help to chart a roadmap to a future that is ambitious but attainable. That’s always my preference.
To that question, I ask back: “If it’s possible, how come almost nobody has achieved it in more than two decades (and certainly not in the last nine years since Forrester coined the definition)?”
It’s not for the lack of trying or for the lack of tooling. Some people may argue that old school automation solutions had failed due to their implementation approach. There’s some merit in that observation. I’ll talk about the impact of automation tools on the success of a project further down in this blog post, but I don’t believe tooling is the main problem.
In these 16 years of experience with automation strategies and solutions, I can confidently say that the single biggest roadblock to automation is the lack of standardization. Lack of standardization for software, hardware, and operational frameworks is commonplace across industry verticals, regardless of the size of the organization. Yet, it’s rarely identified as a roadblock on the journey towards an autonomous IT.
The more heterogeneous an IT environment is, the more vast and challenging becomes the support matrix for automation. CIOs that aspire to automate end to end sophisticated business processes or applications face a herculean effort to glue together too many moving and evolving parts. There is so much to test and support over time that the automation workflows become as complicated and expensive to maintain as a standard software project.
That’s why my primary recommendation for most enterprises always is to start by automating the most elementary applications or processes. That is the only way to return on the investment quickly and build confidence in the automation project.
The decision to exclusively buy or ship applications and services that have fully-featured APIs is a form of standardization, too. It depends on a discipline that is exceptionally hard to enforce, due to market conditions and cultural heritage that is common in the US as it is in Italy, or the UK, or Japan.
There are plenty of other challenges to overcome in adopting automation at enterprise scale. Still, the pervasive lack of standardization alone turns “NoOps” into an unattainable goal for almost everyone, at least as things stand in 2020.
Paths Towards an Attainable Future
The challenge to achieve the “NoOps” nirvana is enormous not just for large end-user organizations. Even cloud service providers, which designed and developed highly standardized IT environments from scratch to achieve an economy of scale, needed years to release and mature the automated services we use today.
And even the most automated IT environment cloud service providers are offering in 2020, their serverless computing platforms, have yet to reach the maturity necessary to appeal to the majority of enterprise customers. AWS Lambda, for example, was launched in technical preview six years ago, and still today it has plenty of room to grow.
So how do you get as close to “NoOps” as you can in a pragmatic way?
I believe there are three parallel paths that many organizations can walk, some significantly more ambitious than others, to inch towards the autonomous IT vision of “NoOps”:
- No(rmalized)Ops: where organizations keep working to standardize their technology stack and automate it.
- No(tMy)Ops: where organizations make standardization someone else’s problem.
- No(Human)Ops: where organizations invent a way to automate without the need for pervasive standardization
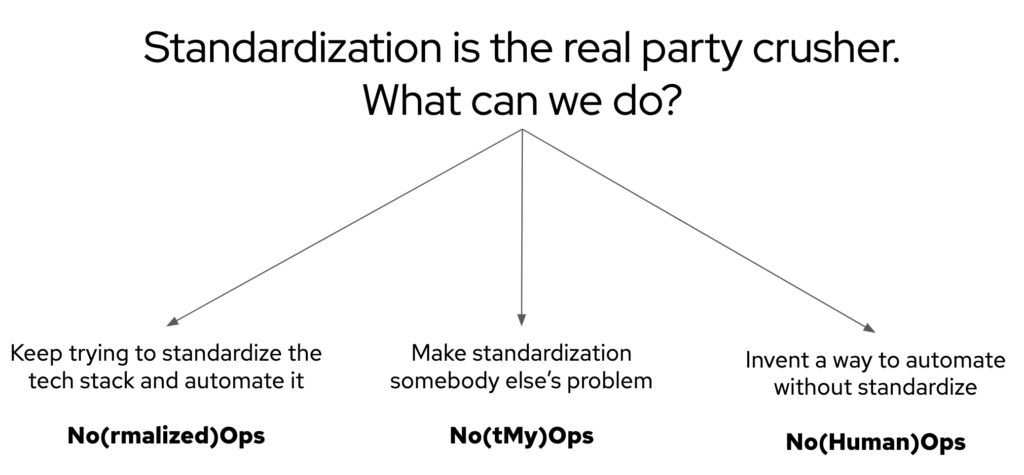
These paths are parallels but uneven. The approaches and technologies that enable the automation of the application life cycle and the ones that permit the automation of discrete operations are at different stages of maturity. Ultimately, the automation journey towards “NoOps” is the matrix resulting from the combination of these two sets.
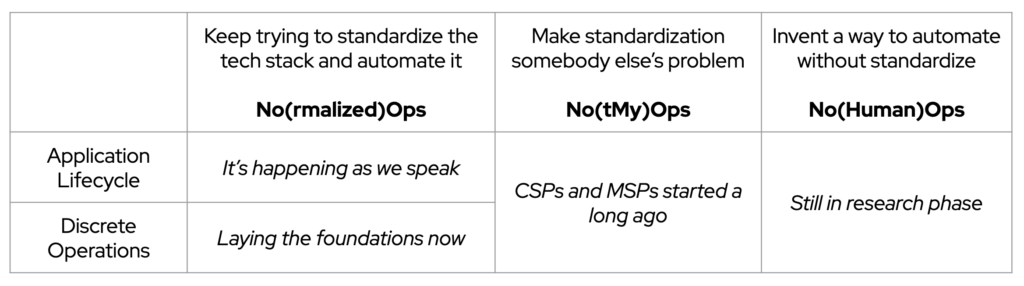
No(rmalized)Ops
As I said, standardizing a complex enterprise IT environment is one of the most daunting challenges a CIO might ever decide to face. I worked with large organizations that successfully standardized portions of their IT and, as a reward, achieved automation levels significantly above average, but they are in the minority.
Fortunately, and regardless of anyone’s ambitions about automation, in the last few years, many IT organizations have started converging towards a set of well-defined, proven-at-scale, and often open source set of technologies. Popularized by a few pioneering web-scale companies, these development frameworks, infrastructure engines, and application platforms, are coming together to offer a modern take on how an IT environment could look like in 2020.

This converging stack is inarguably incomplete (and not just in terms of the examples that I provided in the image) and continually evolving. Yet, it has enough stability and traction among companies with enormous brand gravity to look and feel reliable enough in the eyes of many CIOs, IT Directors, and Enterprise Architecture Teams around the world.
The result is that, in 2020, a lot of organizations around the world are standardizing around a lot more technologies than they did around virtualization engines in mid-2006.
This trend carries risks and opportunities.
One of the risks is that every company betting on this converging stack is giving up most of the competitive advantage they could obtain from a highly customized technology. Of course, a standardized stack frees more resources for organizations to compete on higher level grounds, but do those organizations know how to compete on higher grounds?
As an analogy, think about various computer makers all betting on Intel CPUs. Since performance and battery life are the outcome of a standardized CPU architecture, they have to differentiate through design and user experience. Then think about the newly released M1 CPU from Apple. The latter now can stand out on the merits of design, performance, and battery life after ditching the standardized Intel CPUs.
In reality, what I described is a risk for a tiny minority of the organizations in the world. Few have the vision, resources, and courage to adopt radically differentiated technology stacks.
For everybody else, a converging technology stack rather represents the opportunity to reduce the support matrix for automation. Fewer moving parts to glue together through automation workflows, less effort to maintain and support those workflows, less staff dedicated to automation.
A converging technology stack also has the potential to offer more out-of-the-box integrations across its building blocks. A vast customer base asking for the integration of, let’s say, 20 technologies, especially when many are open source, has significantly more chances to be satisfied than a hundred customers asking 500 vendors to cross-integrate.
With more out-of-the-box integrations across building blocks, there’s less integration effort at the automation platform level.
From Admiring the Problem to Addressing the Problem
Once an IT organization can count on a more standardized technology stack, it can focus on what I consider a first real step towards “NoOps”: the integration between the automation platform and what, these days, goes by the name of “observability” platforms.
Performance monitoring, health monitoring, and logging solutions all collect an increasing amount of data about the various layers of the IT environments. The explosion of metrics to observe is due to three main factors:
- the growing scale of the modern IT environments (stretching as necessary into the public cloud)
- the increasing complexity of modern application architectures – think about the growing of moving parts in the transition from monolithic architectures (2-3) to container-based architectures (dozens) to function-as-a-service architectures (hundreds)
- the accelerating speed of operations, ever more often augmented by artificial intelligence
No human operator can review the overwhelming amount of data generated by modern instrumentation and make decisions promptly.
We have seen this problem for a long time in the cybersecurity space. Firewalls and intrusion detection and prevention systems alone generate so many log entries that security operation teams keep the logging of most rules disabled or at the minimum level. Despite it, security teams manage to review as little of 5% of logged events.
The IT industry has been under the spell of two delusions for at least a decade.
The first delusion is that a set of dashboards can help us solve the problem. All monitoring dashboards can do is help us “admiring the problem”. And in many cases, not even that, as we log and review only a fraction of all systems that we should log and analyze to understand the full extent of the problem.
The second delusion is that our incapability to react fast enough to the enormity of data we are collecting is a human resources problem. Unfortunately, adding more people to the IT Operations team is not going to make a difference because the limitation is in how quickly our brain processes information and formulates remediation plans, not in how many people fit an office.
Paradoxically, if organizations’ approach doesn’t change, the more visibility we’ll try to gain through additional instrumentation of IT systems the blinder we’ll become.
Automated Remediation
The first step towards a more sustainable approach is the integration between observability solutions and the automation engine, necessary to start transitioning from “admiring the problem” to “addressing the problem”.
The step is not an easy one to take. In 2020, the number of monitoring solutions that integrate with automation platforms is exceedingly small. There are at least two reasons for that.
The first reason why we don’t see much integration between monitoring products and automation engines is that the vendors offering both classes of solutions are so focused on their domains (often busy reinventing the wheel) to ignore the bigger picture and the synergy opportunity.
One way to address the market shortcoming is by betting on an automation engine that is modular and extensible. IT organizations should not waste their time writing integrations on behalf of the vendors, but, at the moment, it is the only way to move forward and test the viability of this path towards “NoOps”.
The second reason is that IT organizations are concerned about misinterpreting a metric and executing a remediation action that has disastrous consequences. Automation allows you to err at scale, and rapidly.
One way to mitigate this risk is by creating a library of automation workflows that execute remediation plans if metric A = X or event B = Z, while still manually triggered by a human operator. It is not a solution that can address the pressing need for faster IT Operations I described above, but it is a starting point.
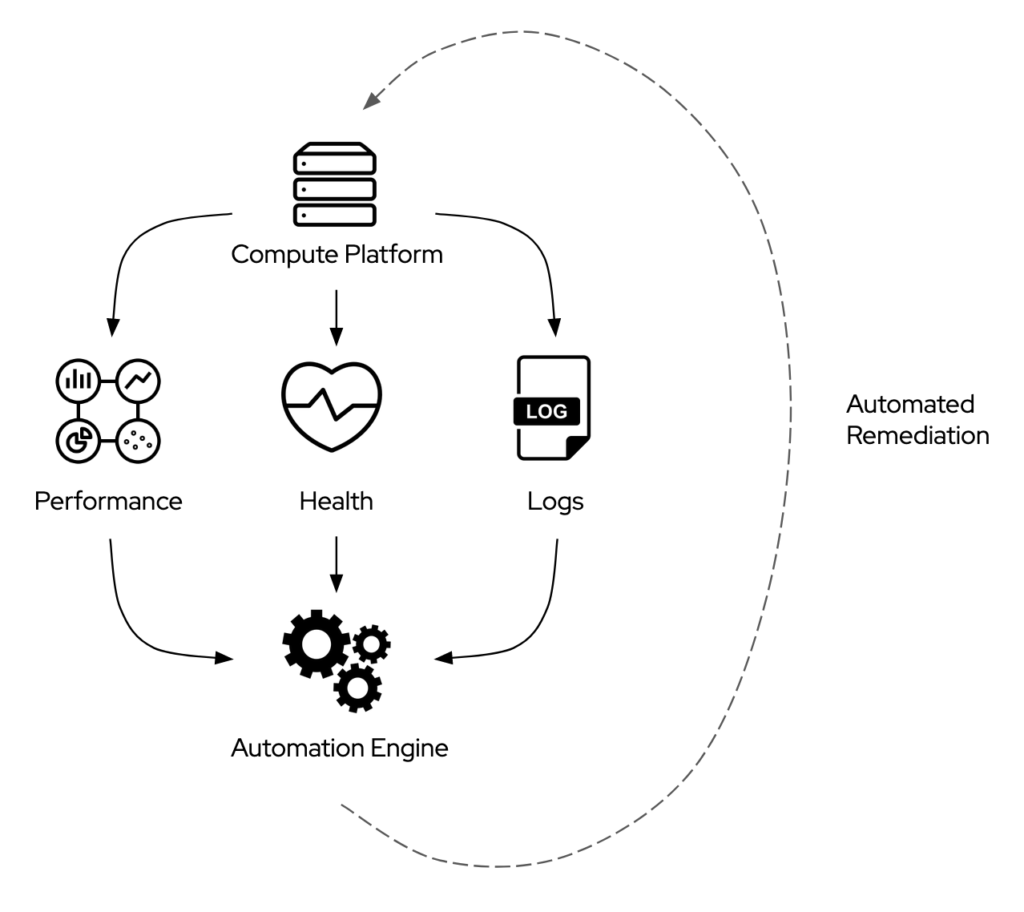
Notice that this approach relies on a pre-existing standardization of the operational framework an IT organization is using. Lacking that, the creation of a library of automation workflows is exceptionally challenging.
In the third path towards “NoOps”, what I call No(Human)Ops, I will describe ambitious ways to leverage artificial intelligence to work around the lack of standardization.
Event-driven Remediation
Even in the presence of a standardized operational framework, eventually, the goal is to automate the execution of the automation workflow, removing the human operator from the equation. To achieve that goal, IT organizations necessitate policies that define certain triggering conditions and a policy engine to enforce them.
At this point, the problem becomes the integration between the automaton engine and a policy engine. This type of integration is more common to find in the market, and customers have seen it in multiple classes of products in the last two decades.
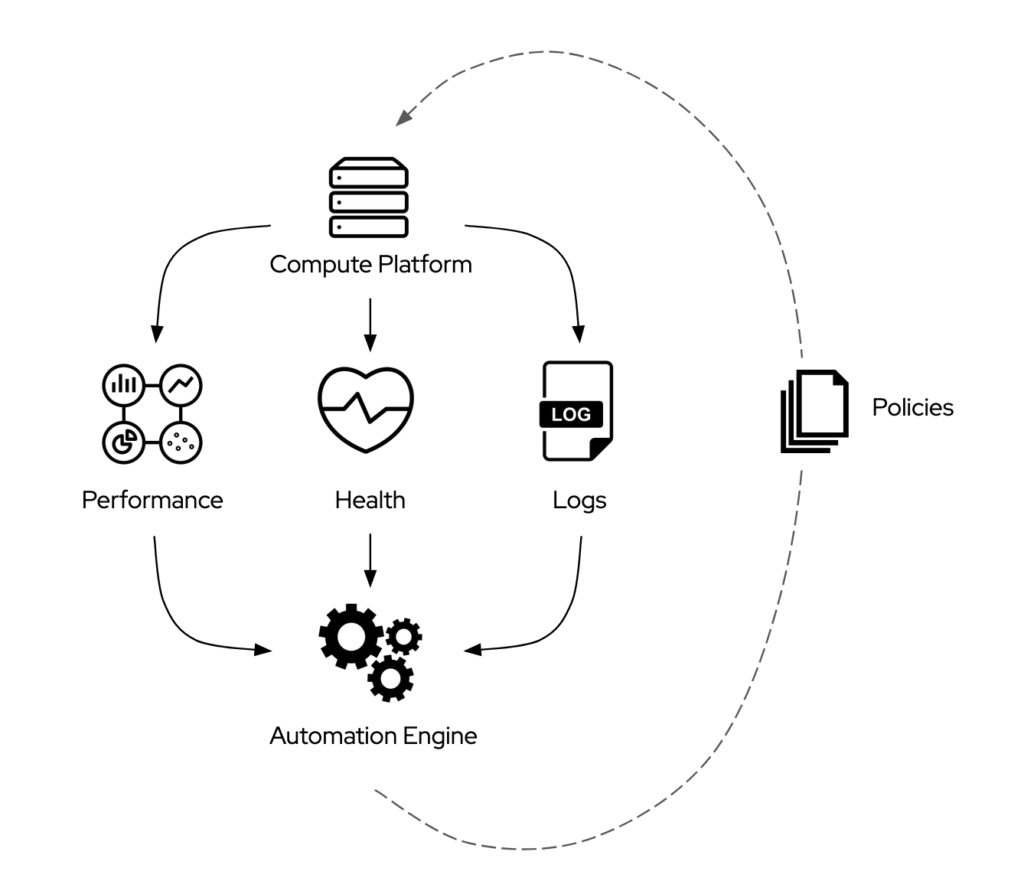
One challenging aspect of this integration is that vendors have always offered policy engines as part of something bigger and more complicated. IT organizations that want to explore the synergy between a policy engine and an automation engine have to invest, for example, in uber-complicated cloud management platforms that they rarely need.
This situation is changing: the IT industry is moving towards leaner and more specific solutions that solve one problem well rather than in general-purpose monstrous monolithic systems that, in theory, can do everything but, in practice, excel at nothing.
Self-Remediation
After the integrations between the automation engine and both observability platforms and policy engines, the next step I would consider is increasing the reliability of the automation engine itself. The automation engine should be able to self-remediate on top of remediating the other systems in the IT environment.
Self-remediation probably is the most challenging goal to achieve. As I intend it, it implies the capability to monitor the automation engine and the execution of the automation workflows, to remediate any failure in each aspect.
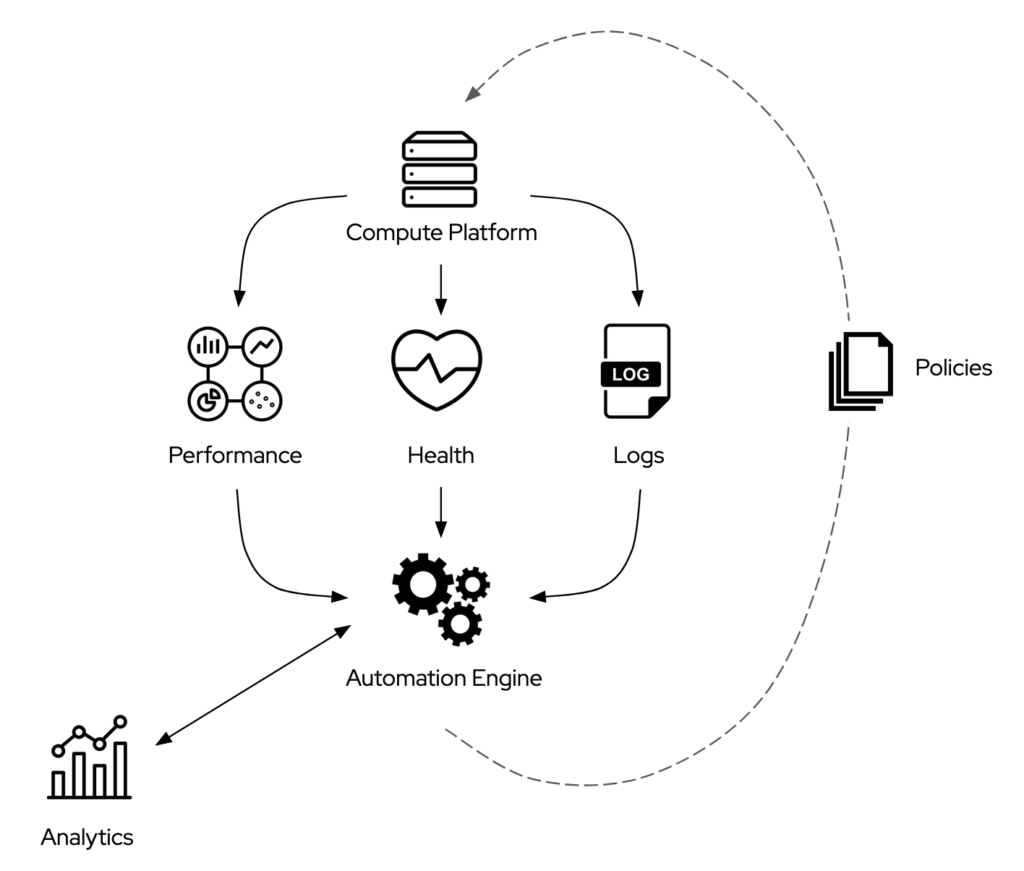
The integration between the automation engine and the observability platforms can be bidirectional. The health metrics could, for example, trigger the deployment of a brand new engine instance in case the existing one is not working as expected.
The self-remediation of the automation workflow is significantly more complicated. The automation engine needs a layer of analytics to understand what automation workflows have failed in their execution.
The errors may depend on how the workflows are written, on unexpected conditions at the target systems, or failures of the automation infrastructure.
Once again, notice that automating the resolution of all these conditions would require a fully standardized operational framework.
The Impossible Task of Standardizing Discrete Operations
What I described so far is mainly beneficial to the IT Operations that focus on the application life cycle. What about the standardization and automation of discrete operations?
Less straightforward than it sounds, automating a discrete IT operation often implies touching multiple solutions provided by disparate ISVs and IHVs.
One of my favourite examples is the investigation or the remediation of a security incident.
In this scenario, a security analyst has to interact with multiple security solutions. In the most optimistic cases: a SIEM, multiple enterprise firewalls, and one or more IDPS.
None of these systems integrates with the others out of the box, unless they all come from the same vendor (and sometimes not even in that case), or a joint marketing and engineering effort between two vendors is temporary in place.
What could take seconds through automation takes hours or days.
It is theoretically possible to write an automation workflow that executes various steps across the solutions involved in the investigation. Yet, those solutions must all expose the necessary access and data via an API, and the IT organization accepts to dedicate significant resources to the maintenance of that automation workflow.
Here, all my previous objections to the “APIs everywhere” vision apply.
There are plenty of similar examples related to discrete operations in core areas like networking and storage that pertain all sorts of use cases, from data wrangling to IoT device management.
There is no industry convergence yet to facilitate the automation of discrete operations. Thousands of software and hardware solutions crowd the IT market with no way to interconnect them efficiently. Various industry constituencies have proposed many interoperability standards in the last decade. Still, they either failed to gain enough traction, or they will take too long to finalize and widespread to be useful.
Lacking standardization and out-of-the-box integration, the best thing IT organizations can do is to leverage whatever APIs their solutions of choice expose and hope that vendors prioritize backward compatibility in their roadmaps. If the backward compatibility is an afterthought, the effort to maintain the automation workflows that leverage those APIs becomes overwhelming for any IT organization.
Rather than waiting for far-into-the-future interoperability standards, I believe that leveraging automation itself as an interoperability layer would be a more pragmatic approach.
IT organizations already use automation to interconnect disparate solutions. If the ISVs and IHVs offering those solutions would provide out-of-the-box integration with an automation engine that is well established in the industry, customers would have significantly less to maintain
Of course, no vendor in the world would voluntarily ship out-of-the-box integration with an automation engine developed by another player. It’s not just a matter of not influencing the technology roadmap of the automation engine of choice. It’s also about the very substantial risk of seeing the automation player leveraging the control on the automation engine becoming a powerful competitor over time. An automation engine can be the foundation for products in many software and hardware categories.
Similarly, the IT organizations of the world would be cautious in adopting an automation engine that promises to be the ultimate integration layer for all ISVs and IHVs in the world but remains controlled by a single vendor. It’s not just a matter of perceived technology lock-in, which makes some CIOs uncomfortable. It’s also about the diminished negotiation power that customers experience any monopolistic scenario.
For an automation engine to become the integration layer, the connection broker, the de facto standardized connectivity tissue of the IT industry, it has to be independently developed and out of control exerted by any vendor.
Luckily, in 2020, the IT industry has produced open source automation engines. Some of these engines are supported by an enormous and vibrant community of professionals and enjoy industry-wide and global-scale adoption among IT organizations.
As these automation engines are open source, any ISV and IHV in the industry can contribute to the roadmap and have a chance to influence the direction of the project. Yet, this alone is not enough.
For a vendor to participate in the effort and ship out-of-the-box integration with the automation engine of choice, there must be some tangible return on the investment from a business standpoint.
In the presence of already significant customer demand, a vendor would have no choice but to comply to stay competitive.
Lacking that demand, vendors considering the out-of-the-box integration with this hypothetical automation engine must see the opportunity to modernize their solutions without investing millions of dollars in R&D.
Through the integration with the automation engine, those vendors must see the opportunity to stay relevant in an IT environment that must be automated to remain functional.
If organizations have no choice but to automate to cope with scale, complexity, and speed of modern IT environments, then there are countless solutions in today’s market that risk obsolescence. That is why I believe the opportunity to standardize and automate discrete operations around a well-adopted automation engine and language is a more tangible and pragmatic way to approach “NoOps” than many alternatives.
Cybersecurity, the area I focused on at the beginning of my career twenty years ago, is especially prone to obsolescence by automation.
In 2020, a plethora of vendors crowd the IT security market with solutions that attempt to solve both decades-old and new problems, but no one seems to be interested in the bigger picture. The CISO of a large end-user organization can go as far as deploying an average of fifty different enterprise security solutions. Yet, as I said at the beginning of this section, these products and services don’t integrate with one other.
This situation, which hasn’t changed in the twenty years I worked in IT, is akin to the attempt to secure a physical building by buying and deploying CCTV cameras, hiring security guards, and training and security dogs.
It would be fine but, as the IT security market stands in 2020, the security guards don’t look at the CCTV monitors, and the security dogs are locked in the basement.

None of the enhancements promised by the wave of new security players that enter the market every year focuses on this problem and the entire industry is in denial, suggesting that the issue is a scarcity of cybersecurity professionals. As I said, this is not a human resources problem, and no additional headcount will ever bring IT organizations closer to the “NoOps” vision.
To illustrate how an open source automation engine could help IT organizations unifying the highly fragmented CISO portfolio, I filed (and was granted) a patent.
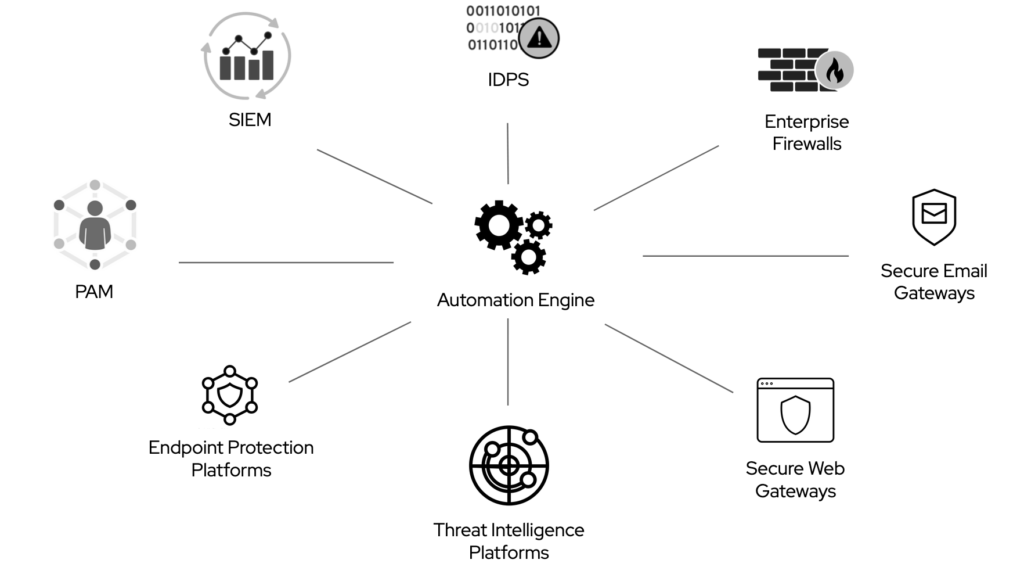
That is just the beginning. The approach described in my patent could equally apply to networking, storage, and so on, for multiple use cases. Yet, it is clear that, even if this approach would extend to those domains, we are talking about a multi-year effort that would require a tectonic shift in the mind of all IT industry constituencies. So far, my proposed approach had some promising traction among cybersecurity market leaders and turned into a commercial solution, but we are very far from the goal.
Some of the steps I have proposed in this path towards “NoOps” are achievable but require much effort. Others require an industry-wide collaboration that may take decades to succeed, if ever.
I hope it is evident that the lack of standardization that most IT organizations suffer prevent them from achieving “NoOps” through this path alone. It is necessary to explore other ways at the same time.
No(tMy)Ops
Given the challenges I describe in the section “No(rmalized)Ops”, the most pragmatic thing that an IT organization can do to achieve “NoOps” is turning the standardization effort into someone else’s problem.
In the last fifteen years, IT organizations have developed growing confidence in outsourcing their infrastructures, and, occasionally, their operations, to cloud service providers.
Some of these providers have offered unprecedented ease of use in delivering and consuming applications, starting a revolution in the enterprise IT world. This revolution is what I called the march towards a “Frictionless IT” for the last six years.
The effort to reduce the friction from the application consumption experience goes well beyond the delivery via a software-as-a-service and a per-hour billing model. For some cloud service providers, that effort has turned into a systematic eradication of complexity both at the technical and business level. Customers have seen out-of-the-box monitoring and management of newly deployed OSes and applications, per-unit licensing terms, app marketplaces integrated with IT procurement solutions, and a myriad of other improvements.
Part of the reasons why cloud service providers (and web-scale startups) have been able to reduce friction drastically is their massive investments in automation. Starting from a blank slate and designing to achieve economy of scale, these companies have been able to standardize their hardware, software (including their API approach), and operational frameworks to an extreme. The extreme standardization, in turn, allowed extreme automation. A traditional end-user organization with forty years of legacy IT technologies to deal with could never hope to achieve the same results.
In a virtuous circle, the reduced friction in application consumption has fostered customer adoption and the revenue necessary for further investments in automation. This virtuous circle has led to fully automated stacks supporting custom-built applications (i.e., “serverless computing” platforms delivering “functions-as-a-service”) and fully automated stacks for commercial-off-the-shelf applications (i.e., software-as-a-service).
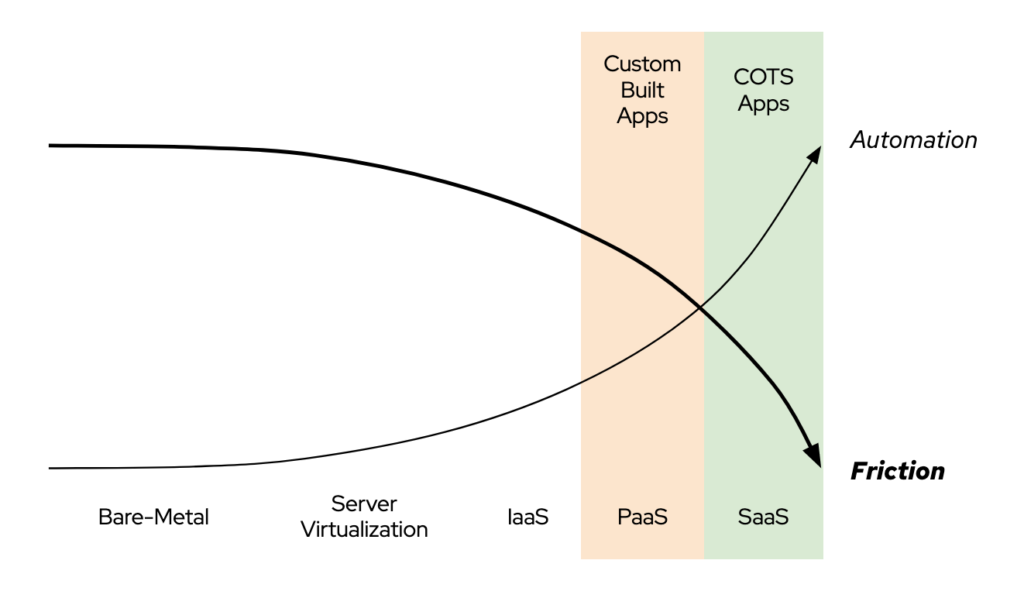
This virtuous circle has been pushing more and more workloads into the public cloud for years. While we are currently seeing a slow down of that hyper-growth, if cloud service providers continue to invest in automation, we might see a new growth phase led by a radical transformation in the workforce.
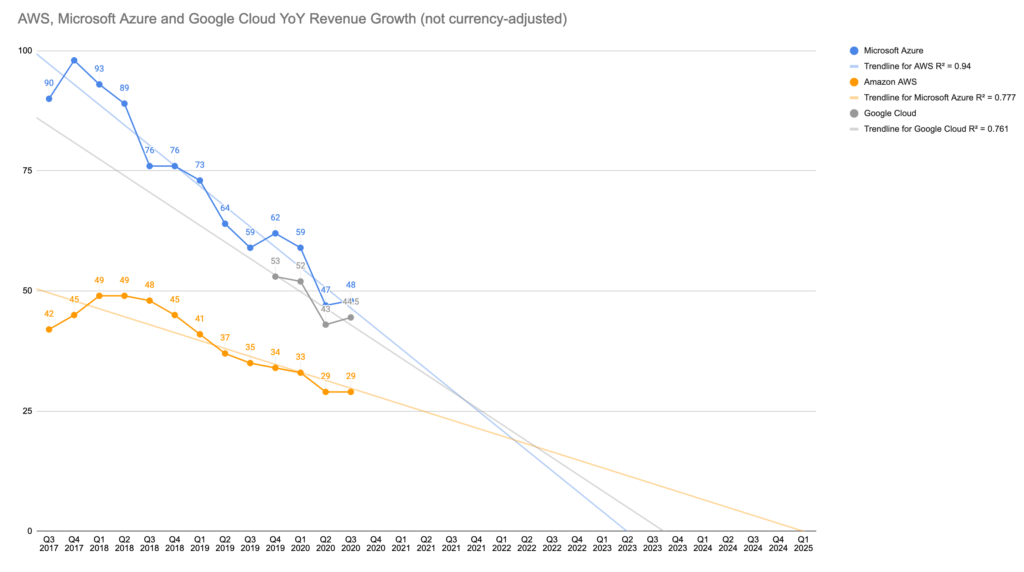
In 2020, the global workforce includes Baby Boomers, Gen X, and Millenials (or Gen Y). These are generations of professionals that have grown accustomed to over-complicated and frustrating enterprise software solutions, accepting them as a fact of life. Millennials have entered the workforce too late to avoid the exposure. Their incapability to accept the status quo have often led to the adoption of cloud services against corporate policies, the modern version of what we used to call “shadow IT”. Yet, the IT organizations of the world have not spared Millennials the disorienting experience of having an Apple Pay in their private life and an Oracle E-Business Suite for expense reports in their business life.
Gen Z will enter the workforce with a significantly less compromising attitude. Gen Z is the generation of touch screens, app stores, one-hour deliveries and, soon, game streaming. Gen Z is a generation that arrives after the march towards a “frictionless IT” has already started. I firmly believe that Gen Z will see convoluted enterprise solutions as the exception to eliminate, not the norm to tolerate. Their preference for products and services that are easiest to use and instantaneous in execution, because automated, will be unprecedented.
If you think that Gen Z expectations and demand is a problem for a distant future, remember how I started this blog post: the definition of “NoOps” is nine years old, AWS Lambda is five years old, and we are nowhere near a final, satisfactory state.
Whatever path IT organizations are following to achieve “NoOps”, what they are building today is going to be used by Gen Z people, both as employees and as customers.
These events are transforming the average enterprise application portfolio into a matrix that is increasingly out of that control exerted by a Central IT and more and more led by the Lines of Business.
Accordingly, the role of that Central IT in end-user organizations is morphing from being a gateway to access cloud service providers to being an auditor of how LoBs consume cloud service providers. But this is a long diversion worth a dedicated post.
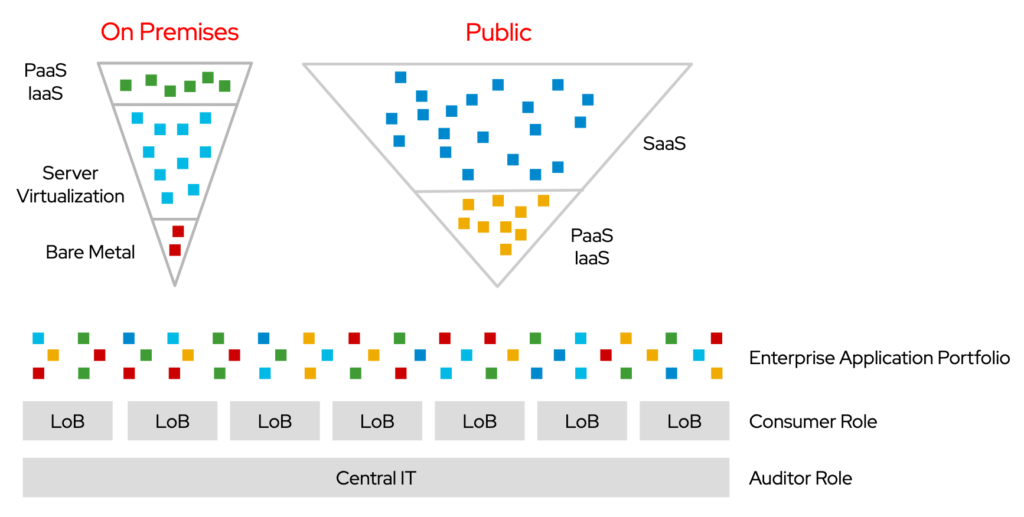
What matters in this context is that Central IT is losing the grip on infrastructure and applications, making the “NoOps” dream of ubiquitous automation even harder to achieve.
Meanwhile, cloud service providers (and web-scale companies) are continuing to automate their environments, adopting and popularizing ambitious ideas like Infrastructure-as-Code.
There is a lot more discipline in software development than in IT Operations. And that discipline leads to faster and more efficient use of IT infrastructures. That is the underlying, untold assumption at the basis of Infrastructure-as-Code. In my personal experience, that is very often the case.
In twenty years of career, the number of large organizations I met with robust operational frameworks is tiny. Where they exist, those frameworks remained substantially unchanged over the years. Conversely, software development methodologies and best practices have significantly evolved and expanded, inspiring and changing the mindset of developers all around the world.
If the assumption is correct, then cloud service providers and web-scale companies can leverage software development methodologies, best practices and tools on their highly standardized infrastructures and achieve unprecedented levels of automation.
Challenges of Infrastructure-as-Code
While Infrastructure-as-Code has the potential to propel customers closer to “NoOps”, I think it is rarely viable for end-user organizations and certainly not the holistic approach that certain vendors promise to be. I see three critical challenges.
The first challenge with Infrastructure-as-Code is that it is incomplete.
As I said, Infrastructure-as-Code has enormous requirements in terms of standardization that only cloud service providers and some managing service providers can achieve and operationalize. These providers can afford an “API everywhere” discipline that end-user organizations cannot ever hope to enforce for the reasons I described earlier in this post.
Exploring the viability of Infrastructure-as-Code is more feasible when the whole IT environment is custom-built and, by mandate, fully exposed through APIs. When that is not possible, like in end-user organizations, customers must rely on automation engines that perform two roles: the ordinary responsibilities of running automation workflows, and the novel duties of abstracting the IT environment beyond what it does natively.
Some automation engines that have focused on the Infrastructure-as-Code idea do the abstraction job exceptionally well, and cloud service providers, web-scale companies, and traditional end-user organizations alike adopt them widely. The problem is that they can abstract only a small portion of the environments, products, and services that an IT organization consumes.
For obvious commercial reasons, these automation players have so far focused on abstracting cloud service provider environments, but only the most popular ones, and only for a subset of the services that cloud service providers offer. Moreover, these automation players have enjoyed the cloud service providers’ “APIs everywhere” approach to build their solutions.
In other words, automation vendors have turned as code only a tiny portion of the infrastructure of the world. Even if end-user organizations could afford to focus just on automating that portion of the world (they cannot), what about discrete operations? What about anything above the infrastructure layer?
Infrastructure-as-Code is not IT-as-Code. Not yet, at least, and not for the foreseeable future. That is why we are starting to see startups that apply the ideas of Infrastructure-as-Code to business applications, regardless of the APIs that they offer.
The second challenge with Infrastructure-as-Code is that it can be alienating.
Several automation vendors have been articulating the idea of Infrastructure-as-Code in many different ways. Some implementations lean more towards concepts and constructs that are familiar to IT Operations teams while others completely align with the language and tooling of software developers.
In my experience, IT Operations teams can learn and embrace the idea of Infrastructure-as-Code quickly. Yet, they will feel alienated in front of a developer-centric IaC automation tool. In that situation, IT operators are not only confronting concepts and techniques never seen before, but they also face a way of seeing IT that they wouldn’t necessarily choose.
Some IT operators may have always wanted to become developers but never thought they had what it takes. Using developer-centric IaC automation tools is their chance to see if they are right or wrong. Yet, there are a lot of IT operators that don’t want to become developers. It’s not the path that they chose for themselves, and it’s not how they enjoy information technology.
IT Operations teams certainly can learn developer-centric IaC tools if that is a matter of job security or team survival. Still, they will not necessarily be happy, evangelize those products, and perform at their best.
I don’t believe that the answer is replacing IT Operations teams with developers, for reasons that I explain in the next challenge. I think that the success of IaC tools depends on finding a delicate balance between introducing novel ways to manipulate infrastructure and retaining the IT Operations team identity.
In my career, I have been fortunate to witness from a vantage point the explosion in popularity and adoption of one automation engine. I have seen it grow until it became one of the top 10 open source projects in the world. It has become so popular among customers all around the world that the expertise to use it is one of the top 10 most wanted skills in the job market.
There are many reasons for this success. One of them is this automation engine has kept things simple and understandable for IT operators, introducing sophisticated automation concepts without alienating them.
The third challenge of Infrastructure-as-Code is that it may lead to unrealistic expectations.
As cloud service providers have become more reliable, secure, performant, and cheaper over the last fifteen years, IT professionals in every role had to learn about cloud architectures. That alone is a daunting task because some cloud providers offer hundreds of services and dozens of ways to achieve the same goal, to the point that none of their solution architects individually has the big picture.
This demand has grown hand in hand with the need to master IT Operations concepts, a core tenet of the DevOps methodology. So a “DevOps engineer”, as we like to define the role in 2020, is requested to be proficient in software development, cloud architectures, and IT operations. Three domains that demand each a lifetime of study and practice to master.
Moreover, in the last five years, the demand for additional skills has grown to the point of expecting developers, IT operators, or “DevOps engineers” to also be proficient in cybersecurity and, increasingly, in data science and artificial intelligence algorithms.

The moment the CTO of AWS goes on stage and declares that security is everyone’s responsibility, he’s implying that every IT professional out there should take the time to learn cybersecurity and factor that knowledge in code development, IT operations, and everything in between.
While the intention is laudable, it is also unrealistic.
Silicon Valley attracts and hosts some of the most brilliant engineers in the world, coming from every country to find fortune. Among them, there are exceptional minds that can indeed be masters in software development, cloud architectures, IT operations, cybersecurity, and AI. Big Tech and web-scale companies pay these talents millions of dollars per year, and they get rich in their 20s, as a quick browse in online forums like Blind confirms.
Outside Silicon Valley, the situation is much different. No country I have ever visited in these years, from Germany to South Korea, from Norway to South Africa, can count on individuals that encapsulate a similar level of expertise. The snowflakes that do move to Silicon Valley for obvious reasons and no end-user organization can compete against those compensations.
The rest of the IT professionals do what they can to keep up, but the chances that they wear so many hats equally well is zero.
Many of them don’t even want to wear so many hats. Very often, in private conversations with developers all around the world, I hear admissions that they just want to code and have no interest whatsoever in the burden of IT Operations. Others admit how overwhelmed they are by the complexity of all the tooling and concepts that the world expects them to master.
Healthcare is a mission-critical job. There is a reason why we have a generic doctor and an army of specialists. The IT industry seems to be going in the opposite direction, and I don’t think it’s sustainable.
So, on a side, Infrastructure-as-Code turns (a portion of the) IT environments into an automation playground. On the other side, companies may expect that whoever accesses that playground learns more rules than he/she can memorize.
Ultimately, Infrastructure-as-Code is a viable albeit partial way to approximate “NoOps”, but it’s infinitely more challenging to embrace for end-user organizations than for cloud service providers and, to some degrees, managing service providers.
Offloading the standardization and automation burden to those providers has a better return on the investment and a faster time to market. Yet, even companies that can walk this path must realize that the No(tMy)Ops is not the ultimate solution to reach “NoOps”.
No(Human)Ops
Standardizing and automating a portion of the IT environment by betting on a converging technology stack is at the core of the No(rmalized)Ops path. Offloading part of that effort to cloud service providers is the main idea of the No(tMy)Ops path. Even if an IT organization is walking both at the same time, there are still many aspects of its IT operations that remain unaddressed.
At the beginning of this long post, I suggested that the third path towards “NoOps” consists of circumventing the standardization problem entirely by making automation flexible enough to adapt to any situation.
This additional flexibility could take many forms. It could help automate hardware and software stacks that are highly heterogeneous and ever-changing. It could help automate processes that IT organizations couldn’t encode in operational frameworks. But how to minimize or avoid the additional burden of a more complex support matrix?
A trainee human operator learns by watching experts in action or by the trial and errors that build one’s experience. In a non-standardized environment, the operator has to memorize so many best practices on how to face the endless permutations to be encountered that, eventually, he/she cannot absorb any more or recall all of them. Moreover, the learning curve is steep, and the time to proficiency is long.
Modern artificial intelligence could overcome these challenges, providing the additional flexibility we need to get closer to “NoOps”.
Here is where things get significantly ambitious. Some of what follows are ideas that no vendor has ever implemented in a product and that live only in patents or on a kitchen napkin.
One of the most likely objections to the ideas I describe in the two subsequent sections is that modern machine learning techniques need an enormous training data set to achieve satisfying results, too much to be of practical use.
While this is true for supervised learning in 2020, there are emerging machine learning techniques that could significantly reduce the training requirements in the next few years. Among the most promising, we have the “one-shot learning” AI model.
While waiting for less demanding machine learning models, I think it is still possible to collect a non-insignificant amount of training data to explore the viability of the following ideas.
AI-Generated Workflows
Ultimately, an automation workflow is the encoding of a series of steps to execute to achieve a goal. If an IT organization has a robust operational framework, the recommended steps to achieve many goals are already defined, and the conversion into an automation workflow is relatively easy.
Before the steps to achieve a goal get encoded into an operational framework or an automation workflow, an IT operator executes them, with some variation, across multiple CLI- and GUI-based applications.
It is possible to configure a command prompt to log the interaction with a CLI-based application and use that log to extrapolate the steps to automate.
Similarly, it is possible to record the activity of a mouse in a GUI-based application and replay it in an automated fashion (think about the old school macros or the modern Robotic Process Automation solutions).
Both processes have strict requirements, imply a lot of manual labour, and are not complementary to each other. As my previous example about security threat investigation illustrated, discrete operations don’t necessarily start and terminate within the boundaries of a single application. More likely, IT operators accomplish whatever task in their todo list by interacting with multiple applications as part of the same process. The hopes to automate this cross-application process via APIs is most certainly doomed to failure and leads to all the issues I described earlier in this blog post.
It is also possible that the IT operator repeats a specific task often enough but has yet to realize that it is a prime candidate for automation. The missed realization may depend on lack of skills in seeing the automation opportunity (i.e., “I don’t think I can automate this process because I’m unaware of feature X”). It might also depend on a lack of awareness about a pattern that exists, but it’s not yet evident.
What if an AI could observe what an IT operator does on-screen, identifying different applications and commands through computer vision in the same way self-driving cars recognize road lanes and traffic signs?
Permanently watching, the AI could potentially understand when a process starts and ends. Once the computer vision captures the steps of a process, it is theoretically possible to convert them into instructions for an automation workflow.
The AI could also identify processes that are not identical but lead to the same outcome (a bit like computer vision can correctly label various types of dogs as “dog”), surfacing undiscovered patterns. Once that pattern is exposed, the AI may highlight the opportunity to create new automation workflows to the IT Operations team.
In both scenarios, the AI might need additional help to understand what is the optimal way to write the automation workflow. A second AI with a different job may provide this type of support.
As I said before, some automation engines can count on very active open source communities and significant market traction. This popularity can sometimes translate into a vast collection of automation workflows that individuals and companies share through centralized repositories, both public and private.
The workflows available in these repositories encode the steps necessary to automate many typical tasks, and they often achieve the same goal in slightly different ways.
An AI leveraging natural language processing (NLP) algorithms could autonomously parse automation workflow repositories and learn how IT professionals encode many tasks.
So we have two AIs. One leveraging computer vision that learns about the steps an IT operator executes to achieve a goal. And one leveraging NLP that knows how IT operators usually automate various processes.
Maybe it is possible to validate what the former AI has learned against the knowledge the second AI has accumulated. The result would be a draft automation workflow, automatically generated, that a human operator can review and finalize.
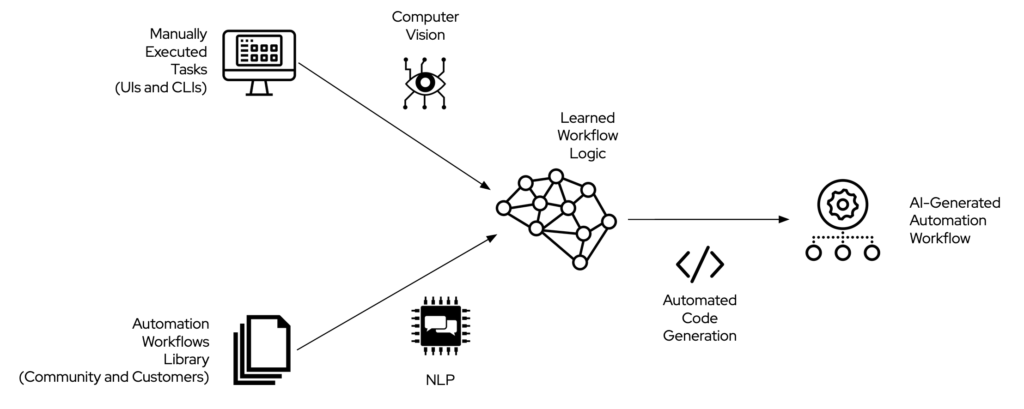
Discussing this idea, or the next one, in details is beyond the purpose of this blog post, so I will leave out details about what type of AI algorithm to use or the privacy implications of an always-watching AI.
While these problems are of utmost importance, the point I am trying to make is that AI could circumvent the lack of standardization, in terms of operational framework in this case, without adding significant overhead for the IT Operations team.
AI-Driven Remediation
Artificial intelligence could also learn how to find more efficient ways to execute the steps necessary to achieve a goal, with or without an existing operational framework.
We need to go back to my security orchestration example. In that scenario, different security solutions interoperate through the out-of-the-box integration with a common automation engine. A security analyst encodes the steps of a threat investigation or attack remediation in an automation workflow which is executed manually or upon triggering conditions.
The interesting fact is that there are multiple ways to achieve either goal.
IT organizations can block an ongoing cyberattack, for example, by changing the rules in an enterprise firewall, or by placing a compromised machine into a quarantine network, or by reconfiguring network and DNS settings.
Different security teams remediate an attack in different ways, according to industry best practices and personal experience, but is it the most efficient way to proceed?
IT organizations define efficiency after their business strategy and the KPIs that matter the most to them. In this example, the most efficient remediation might be the one that has the shortest time to resolution or the one that minimizes the number of compromised hosts in a specific section of the network.
The point is that, like in real life, different steps may lead to the same outcome and IT Operations teams (or Security Operations, in this case) do not necessarily execute the most efficient ones lacking the standardization offered by a robust operational framework.
Now imagine an artificial intelligence that is in charge of the security orchestration of my example. This AI has the freedom to combine pre-approved automation steps to remediate a cyberattack.
Also, imagine a network of customers, all deploying the same automation engine, and all anonymously sharing data about the method chosen by the AI to remediate a cyberattack.
The same attack (for example a ransomware worm like WannaCry) eventually hits multiple customers in that network, and the AI remediates it in alternative ways. In this situation, the AI might discover a more efficient sequence of remediation steps and propagate the new best practice across the network of customers, including the ones not compromised yet.
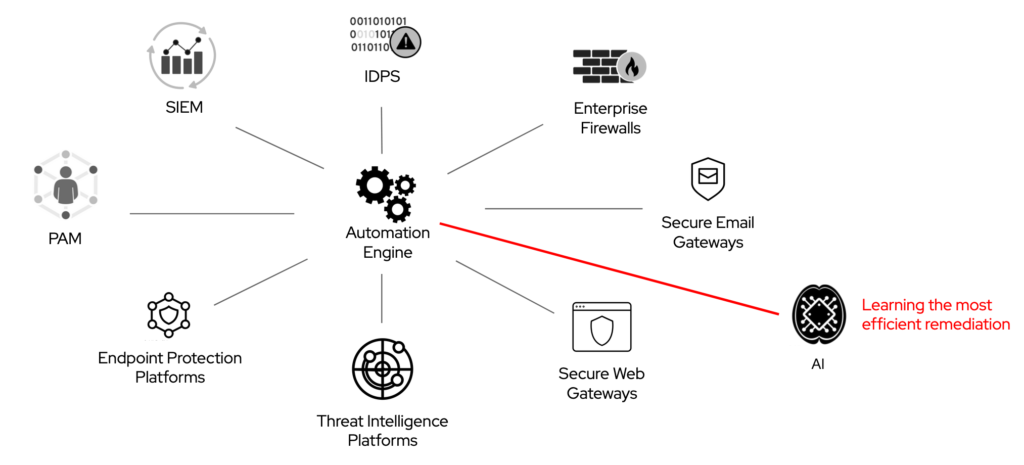
If viable, not only this approach would help the security team think out of the box, but it would also learn and adapt faster than its human counterpart to any variant of the threat.
The standardization benefits of an operational framework would become minor compared to an AI-driven automation that adapts to unique scenarios without additional IT operations overhead.
As I said, these ideas are unproven and far away from fruition. They serve as examples of an alternative to many approaches proposed in the last decade to achieve the level of automation foundational for “NoOps”.
The reason why I believe some of these ideas are more pragmatic than others is that they try to build on top of a world that already exists. Or at least this was my intention. Some ideas and implementations I described in this blog post instead evangelize a full reset as the only way to move forward.
I don’t believe that a full reset is a viable approach to “NoOps”. In part, because it discounts the financial and political implications, at the CFO and CIO level, of ditching previous investments. In part, because it creates the slippery slope of a call for full reset every few years, which would be more disruptive than beneficial for the business. In part, because in my many conversations with Fortune 500 and Global 2000 enterprises, I always heard customers telling me that their top requirement for new technology is the integration with the existing one.
Whether the ideas I propose here are viable or not, I hope I made clear that even using artificial intelligence to inch towards “NoOps” is a very arduous path.
Summary: A Roadmap Towards an Approximation of NoOps
I have a firm conviction in the potential of ideas like Infrastructure-as-Code, self-healing IT systems, or AI-driven automation. I also believe that none of those ideas alone can lead to the ultimate vision of an autonomous IT as intended in the broader definition of “NoOps”. Those ideas must work together, converging after a big picture that goes beyond the agenda of any specific IT vendor.
The problem I see is that the potential of those ideas will take decades to emerge. Until that time, my years of experience working with some of the largest companies in the world on IT automation projects suggest that “NoOps” is an unattainable goal for the overwhelming majority of IT organizations.
What companies can hope to achieve is a vague approximation to the holistic vision behind “NoOps” via a series of tricks:
- standardize as much as you can by betting on the current converging technology stack
- offload part of the standardization problem to cloud service providers and managing service providers
- creatively use artificial intelligence to circumvent the lack of standardization
It will be interesting to see how much has changed in 2025, and then in 2030. Hopefully, the IT industry will be able to evolve in ways I cannot anticipate.
* From the Forrester Research paper titled “Augment DevOps With NoOps”: “NoOps will not replace DevOps; rather, it is an evolution of the release management aspects of DevOps. NoOps is not about the elimination of ops; it is about the elimination of manual hand-offs and low-value, rote administration. NoOps requires strong ops participation in strategy and planning but aims to minimize manual involvement in operational concerns for developers, a change that is especially important for business developers who are particularly enthusiastic about cloud apps.”
↵